Анализ частотности букв и биграмм в русском языке
Описание проекта
Данный проект представляет результаты анализа частотности букв и биграмм (двухбуквенных последовательностей) в русском языке. Анализ проведен на основе данных из Национального корпуса русского языка (ruscorpora.ru).
Методика получения данных
Частотность букв и биграмм была рассчитана с использованием Python-скрипта, который:
- Фильтрует только современные русские слова
- Нормализует регистр
- Подсчитывает встречаемость каждой буквы и биграммы в словах с учетом их частоты в корпусе
- Рассчитывает относительную частоту каждой буквы и биграммы
Алгоритм учитывает частоту слов в корпусе при подсчете частотности букв и биграмм, что дает более точное представление о реальном использовании букв и их сочетаний в русском языке.
Скачать исходные данные
Визуализация результатов
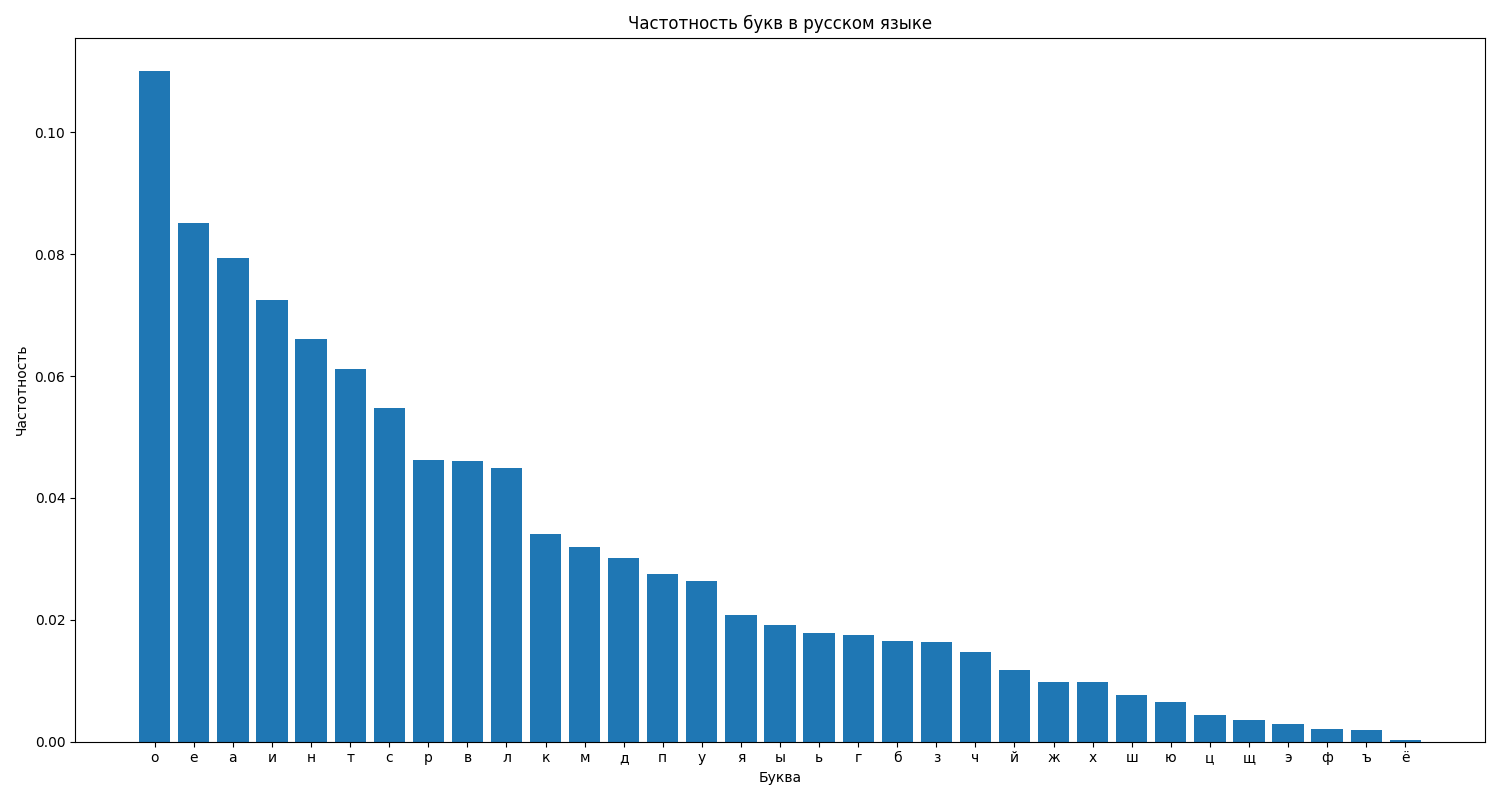
Частотность букв в русском языке
На графике представлена относительная частотность каждой буквы русского алфавита. Можно увидеть, что наиболее частыми являются буквы "о", "е", "а", "и", "н", "т", "с". Наименее частотными - "ъ", "ф", "э", "щ", "ё".
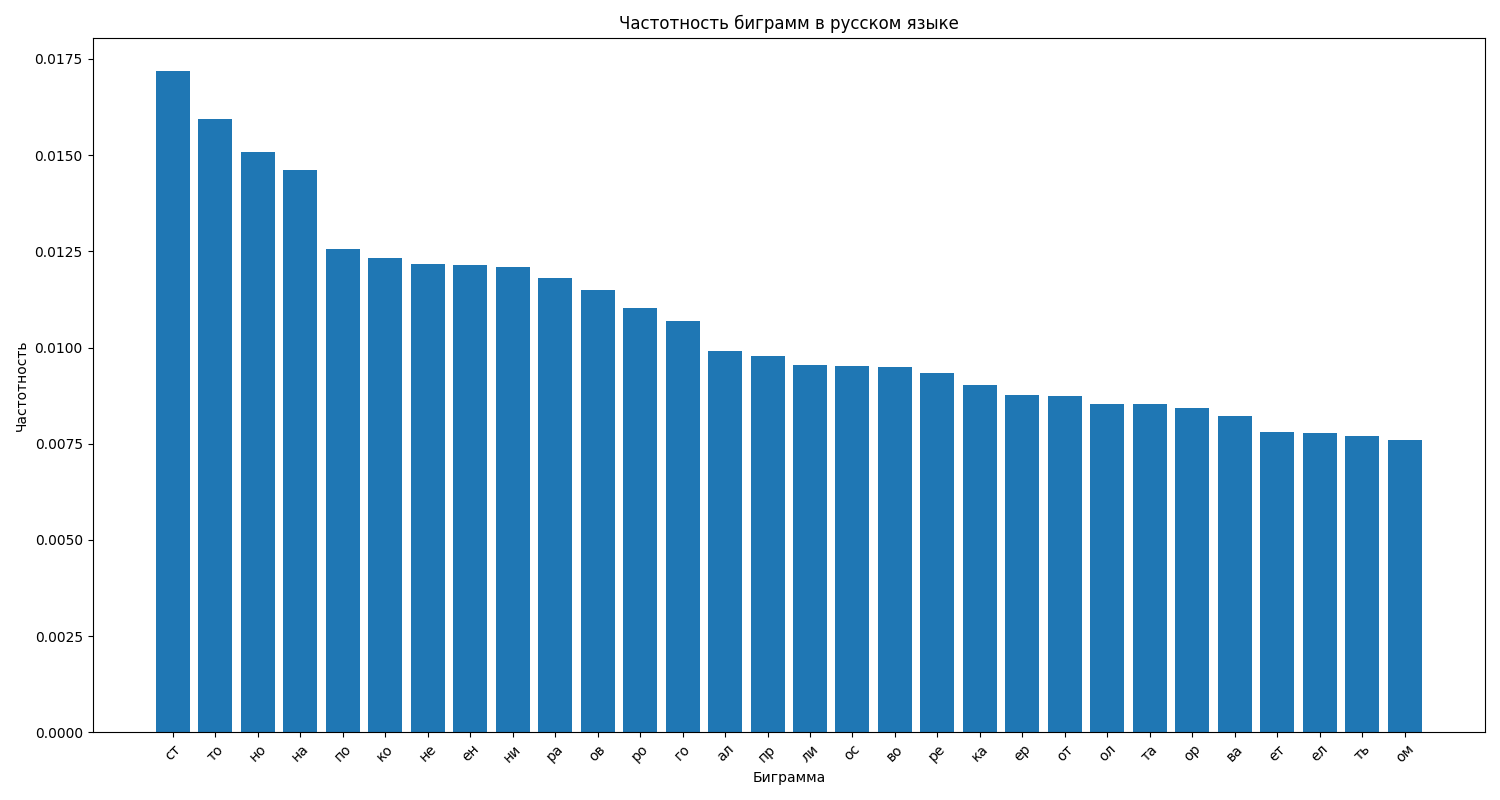
Частотность биграмм в русском языке
На графике представлены 30 наиболее частотных биграмм (сочетаний двух букв) в русском языке. Наиболее частыми биграммами являются "ст", "то", "но", "на", "по".
Комбинированный график
Для сравнения частотности букв и биграмм, вы можете открыть комбинированный интерактивный график. Это позволяет лучше понять, как частотность отдельных букв соотносится с частотностью их сочетаний.